Running a small fleet of agents in the house
What I've built on top of someone else's agent runtime, and why the discipline matters more than the kit.
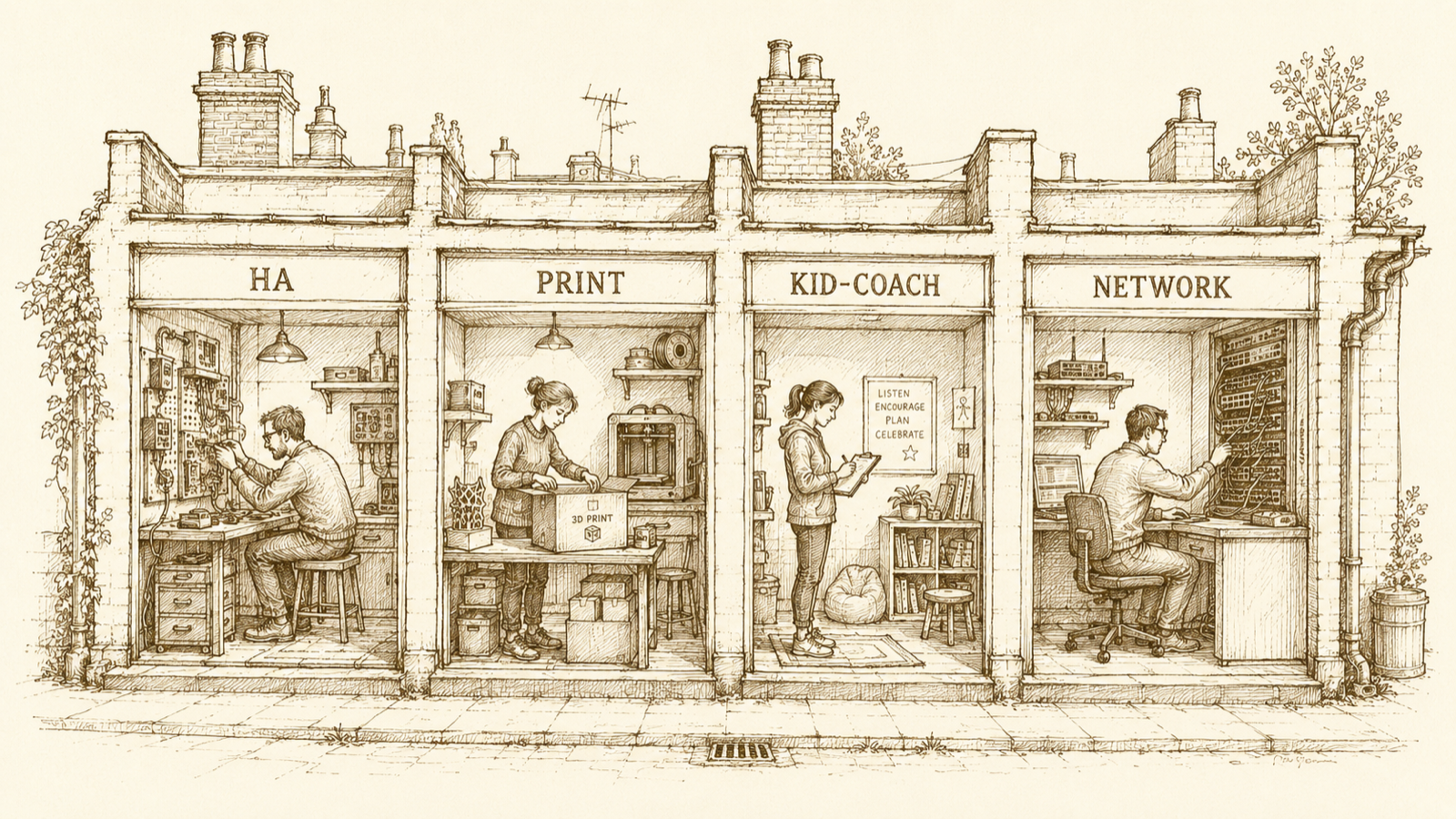
I run a fleet of AI agents at home. Not one helpful chatbot — a fleet: a household assistant, a coach for my son’s Type 1 routine, a couple that help me manage my 3D printing hobby, a couple that admin a local camera club, and a small bench of dev-facing helpers I lean on every day.
The runtime they all sit on is OpenClaw. I didn’t write it. Someone else did, well, and I had the good sense to use it.
What follows is what I’ve actually built on top of it, what I’ve learned about running real agents around a real family, and why I keep saying fleet instead of agent.
Why a fleet, not an agent§
There’s a pull, when you start with this stuff, toward building one big do-everything assistant. The reasonable instinct: less to maintain, fewer surfaces, one mental model.
I’ve ended up at the opposite. The discipline I keep coming back to is one job per agent:
- The front-door agent doesn’t know much; it knows who to route to.
- The agent that handles my son’s routine doesn’t know anything about the 3D printer.
- The agent that catalogues my prints doesn’t know my child’s blood sugar history.
- The agent that opens Jira tickets has no business near my Cloudflare API token.
Separation isn’t aesthetic. It’s containment. When the lights-and-temperature agent does something stupid, the worst case is the lights and temperature get weird for half an hour. When everything is one agent, the worst case is everything.
This is the same argument as small services over a monolith, written in a different domain. Familiar muscle, different problem.
The shape§

The fleet is, roughly:
- A front-door agent the family talks to.
- Specialist agents behind it, each scoped to one domain.
- Identity per agent. Each one has its own credentials, its own audit trail, its own rate limits.
- Skills as versioned Markdown, in a public repo. Anyone can audit what an agent is told. I can
git logan agent’s behaviour and see who changed what. - Secrets in SOPS, age-encrypted, per-agent. Out of the runtime config entirely.
- Backups on cron to GitHub. I’ve restored from them. Twice.
The runtime sits on a Mac mini in the corner of the office. Headless, always on, deliberately boring.
What’s actually running§
A short, deliberately vague tour:
- The household assistant — handles routing, calendar nudges, the “is anyone in?” questions. Doesn’t try to be clever; tries to be reliable.
- A coach agent for my son’s routine — in design, not yet live, deliberately taking my time on it. Diabetes-aware. The boring rule that survives every iteration is don’t make the child interpret medical signals alone — anything health-critical pages parents, not him.
- A handful of agents for the 3D printing hobby. Keep the print queue tidy, catalogue what I’ve made, track what filament I’ve got left. Boring agents doing boring work that used to eat my evenings.
- A couple of agents that admin a local camera club. Member submissions, mostly. Not glamorous; very useful.
- Infra helpers. Open a Jira ticket, check a Cloudflare tunnel, watch a deploy. The least impressive agents are the ones I lean on most.
I’m being deliberately vague about prompts and configs. The interesting bit is the shape of the operation, not the recipes.
What’s quietly switched off§
A few agents sounded good on a whiteboard and quietly didn’t earn their keep. The pattern is consistent: the value wasn’t where I expected, or the toil removed didn’t outweigh the toil added.
Examples in the parked pile: weekly-summary agents I never read, proactive nudges that became the new annoyance, one or two experiments where the privacy footprint wasn’t worth it.
A live agent has weight even if it does nothing — it shows up in logs, in backups, in my own attention. If it isn’t pulling, it goes.
The sentence I keep coming back to: the goal isn’t more agents; the goal is less toil. If a new agent doesn’t directly reduce a specific kind of toil, it doesn’t ship.
What I’d want from any runtime, in hindsight§
If I were choosing a runtime again now, the things that have actually mattered are the boring ones:
- Per-agent identity, properly. Audit logs, rate limits, credentials. Not a “user” abstraction stretched to fit.
- Skills you can read, diff, and review. Plain text. Source-controlled. No prompt-admin UI.
- A backup story you’ve actually tested. Tested, not theorised about.
- A way to gate which agent can do what, without per-call ceremony. Most agents should be allowed to do almost nothing.
Notice none of those are model choice, vector store, or framework. Those are answerable later. The structural ones cost you for years.
Why this is on the site§
Two reasons.
One: there’s a lot of noise about agent frameworks at the moment and not much honest writing about running them. Most posts you read are either day-one demos or marketing. I’d rather write the boring middle.
Two: when I look back at the things that have made my house quieter in the last year, almost all of them are these small one-job agents and the discipline around them. That’s worth writing down, even if no one else reads it.